今天要转载一篇文章,这篇文章在“资讯视觉化”这一课题中占有重要的地位.
视觉化:追寻数据美学 (Visualizing:tracing an aesthetics of data)
作者:
we make money not art 编译:
we need money not art原文地址 译文地址
Part2
-------------------------------------------------------------------
那么,这门艺术的现状如何?如果平面设计师、信息设计师一干人等开始在某个社会背景下运用这些工具,会怎样呢?
第一个例子是关于2006年夏天黎巴嫩和美国发生冲突的事件。新闻披露了当时只有英国,以色列和美国拒绝在联合国命令下停止对峙。全世界的报纸几乎都报道了此事,然而只有其中一份最有视觉冲击力:

中东危机:谁支持立即停火?(报纸的封面参见
这里和
这里)
如果我们把它转换成文字,则新闻的冲击力将会大大不同。如今的报纸正在越来越多地使用到数据视觉化。
当然,在艺术和科学领域,同样能找到许多其他例子。比如:
不平等(Inequality), Josh用
Processing制作的作品,像清清楚楚地表示出:1960年美国的CEO们的工资比平均工资多处41倍,到了2001年他们的收入比普通工人多出411倍。


如果把相同的数据放到传统的统计图标中,你能得到相同的信息,但却减少了立刻显现的震撼与互动性。
(顺便提一句,artificial.dk有这位艺术家一次很棒的
采访,还有一段他在“影响力”[The Influencers]会议演讲的视频)。
信息设计也有它的局限性:数据的设置太过统计化,而数据的集成又太简单,缺乏互动。于是产生了一门将会影响到制图、平面设计等横向领域的新学科。
萌芽于九十年代的新视觉化实践,介乎数字信息分析和表达策略之间。它用鲜活的例子告诉人们,数据视觉化不仅可以应用于抽象数据的解析,还能应用于其他领域的解读和诠释。

例如,
Ben Fry想知道“到底美国的邮编是怎么分派的?”这样一个简单问题。答案便是
邮政解编(zipdecode)——邮政编码系统有多复杂,它就有多简单。
 Bradford Paley
Bradford Paley曾经担任华尔街视觉化系统的设计负责人,他的另一个作品
文本弧(TextArc) 很好地显示出数据视觉化的跨学科混合风格。文本弧是一个让人着迷的文本视觉化呈现作品,整个文本只在一个页面中显示出来——在这个例子中,是爱丽丝梦游仙 境和哈姆雷特。Paley跳出原著,并把它转换成空间结构,让空间文字的位置来显示它们各自的重要性,把它们包围起来的弧线则描摹出文字之间的联系。
另一个例子:
色彩密码(Color Code)是一幅互动树图,上面有33,000个英语名词,每个单词用一个长方块表示。方块的颜色就是用图像搜索引擎搜这个名词的时候,结果中显示的平均颜色。此外,由于文字用类聚方法处理过,所以类似的单词在图上挨得很近。

JL接着展示了我迄今最喜欢的信息视觉化作品:
Marcos Weskamp的
新闻地图(Newsmap)。
这个应用程序可以从视觉上反映出谷歌新闻聚合器中不断变化的新闻全景。它把信息分割成容易识别的条带,当这些信息呈现在我们面前的时候,我们能够看出不同文化背景下新闻报道形式的差别,以及来自全球各地的新闻片断。
美学上的处理采用了语义学的诠释方法,它根据对应的语义,以一定的方式来组织信息。
 Jonathan Harris
Jonathan Harris的
10×10, 是一个互动型而且不断变换的世界快照和定义时间的图片展示。这个系统时刻观察国际新闻来源,每个小时,它都会收集100个被认为是全世界最重要新闻的词语 和相关图片,并且把所有信息用100幅小图表示出来。10 x10经年累月地收集这些一小时更新一次的报道,同时把它们并排放在一起,拼凑出一块人类生活的“百家布”。
JL指出,这种呈现数据集的形式太过随意。显然还有更多办法来更好地表示一组数据以及数据间的关系。
此外,数据视觉化也是视觉的化身;是对不同语言所表达的一系列进程的诠释——有些人称之为
数据开采(data mining);是从数据海洋中提取有用信息的科学。数据开采正被用作一项技术,它的应用领域从科学界慢慢转移到一个更加广泛的社会和文化导向层面。
 《魔鬼经济学
《魔鬼经济学:一个流氓经济学家发现了一切事物的隐藏面》(Freakonomics: A Rogue Economist Explores the Hidden Side of Everything)是一本在任何机场都能看到的读物。它由经济学家
Steven Levitt和 纽约时报记者Stephen J. Dubner于2005年出版。在这本书里,Levitt使用了统计学分析技术来回答一系列的问题(其中有些相当令人吃惊)。此书一度引起争议,特别是关 于解释纽约在90年代犯罪率急剧下降的那一章。在书的作者看来,使暴力事件的发生减少的
主要原因其实是70年代的堕胎合法化。
其它例子:通过
安然探测器(Enron Explorer),跳板代码(Trampoline)工程师提供了多达200,000封在丑闻调查期间公布的
安然公司内部电邮。这个系统生成每个雇员的社会关系网络图,使用户看到这些社会关系网络可能指示着导致这架美国能源公司倒闭的原因。
安然事件(简单
介绍)标志着新闻业技术的转型:从讲述事实的时代到过滤数据的时代。
水门丑闻的曝光是由于隐藏的信息被挖掘了出来。安然事件则不同,它的曝光始于一个新闻工作者对公共数据进行分析的时候,在某一时刻意识到显示出的数据与安然公司本来要进行的活动有出入。
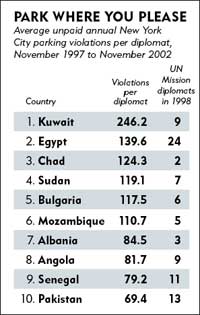
另外一个非常简单的例子告诉我们怎样用一串数据来讲故事。腐败被看作是阻碍经济发展的一个主要因素,但是比起法律强制性,文化规范在控制腐败中的重要性却鲜为人知。为了解释清楚这两个因素,两位
研究人员走遍了几千位来自全世界的驻纽约外交官的办公室。美国的外交豁免政策意味着违规停车可以免交罚金,因此研究人员认为可以把文化规范看成唯一的影响因素(至少他们相信是这样)。他们调查的
结果如左图所示。
为了强化这种常见的文化偏见,作者还指出,拿到罚单最少的外交官来自挪威,丹麦,瑞典等国家。
还有个
案例来 自一个《连线》杂志(Wired)的记者,他认为恋童癖者(在美国,已定罪的性侵犯数据是公开的)跟MySpace用户群有关。于是这位记者编写了一个程 序脚本,搜寻在网络社交平台上注册的性罪犯。在他找到的罪犯当中,有一些和朋友以及家人在一起,但其中有3个正在勾引儿童。这位记者所做的工作加速了对 Andrew Lubrano这种人的逮捕。程序的代码已经
可以在此获取。

有个很有名的数据管理方法叫做
标签云(tag cloud)。例:
美国总统演讲标签云概括出历届美国总统在演说中使用频率最高的一些单词,从而反映出他们眼中历久常新的重要问题。
信息视觉化还有一个大显身手的时候是当它扮演
社会关系网图(sociograms)的角色的时候。这时,它能够揭开人际关系的面纱,显示出人际关系中的某些结构特征。

艺术家Mark Lombardi对于复杂的社会构造和事件巧合非常着迷,他把对两件事物的激情一起融入了他著名的共谋(Conspiracy)地图中,用于解构诸如水门丑闻、梵蒂冈银行丑闻(译注:1982年意大利安保信银行[Banco Ambrosiano]涉嫌洗黑钱倒闭,而梵蒂冈银行是安保信的最大股东。英文资料参见这里。)、伊朗门丑闻(译注:里根时代爆发秘售伊朗军火所得,收入接济尼加拉瓜右翼叛军的大丑闻。)等事件。
让我们我们回想过去十五年间最著名的媒体艺术作品:
Josh On的“
他们统治”。这个应用程序揭露出美国统治阶层之间的一些关系;同一群领导者如何出现在不同但都实力强劲的美国企业高级管理层中;一些人是如何雄踞500强公司的第5、第6、第7位的。它允许用户浏览这些环环相扣的人名地址册,在管理层和公司中进行搜索。
像“他们统治”这样的作品,其优点不在于能“提供问题的答案”或是告诉人们高居管理层的人彼此是敌是友,而在于艺术化地表现出我们身处现实的复杂性,不然的话,错综复杂的现实会让人理解起来伤透脑筋。

由
Ingo Günther创作的
世界处理器在地球仪上标出各种社会、环境和政治世界性参数的地理分布:包括国际移民、国家债务、财富分布、CO2排放量最高的国家等。
芝加哥犯罪数据库(Chicago Crime database)从谷歌地图搜集那些已被警方发现的全国犯罪活动数据。
意向数据库(The Database of Intentions,由John
Battellle命 名)是一个数据创造、分类和传播的重大改变,它不再是科学、经济学或者统计学处理的结果,而是变成了一个社会学现实。我们每个人都成为了一个数据生成器, 这可多亏了web2.0和琳琅满目的搜索引擎。每次我们在搜索引擎上查找一个关键词的时候,我们获取了信息的同时,搜索引擎也从我们这里获取到了信息:比 如我们需要什么,我们在找什么,我们喜欢什么,我们害怕什么,我们担心什么等等。
糟糕的例子则是AOL(译注:“美国在线”网站的简称。)是如何将大量关于用户咨询的数据
泄露出来的。虽然他们事后进行了
道歉,却为时已晚。

Mark Hansen和Ben Rubin的
聆听式邮件(Listening Post)诗意地给数据流安上了一张面孔。这个装置从聊天室、公告栏还有其他公众论坛实时摘选文本片断,用声音合成器读出这些文字,并且通过200多个悬挂在垂直架上的电子屏幕显示出来。
由
Stamen开发的
挖掘实验室(Digg Labs)可以实时视觉化转译社区活动。
不过,你怎么评判一个社会活动的质量呢?
 Golan Levin
Golan Levin在他的杰作“
甩就甩了”(The Dumpster)中告诉人们怎样将少年情侣浪漫的分手方式进行视觉化。
还有一个某种程度上与之类似但更有抱负的作品:
我们感觉不错(We Feell Fine)出自
Jonathan Harris 和
Sep Kamvar之手,通过收集关于网络用户在日志中流露的情绪数据,来研究人类的情感。他们编写了一个程序脚本,从最新发布的日志条目中搜索“我觉得”“我感到”一类的短语,然后记录下整个句子,辨认出句子中表达的具体“感觉”(譬如伤心、快乐、沮丧等。)。
JL用了一则关于“他们统治”的轶事来收尾。显然有两类人会去使用TR:对这个程序感兴趣的网络用户,还有本身就是TR的一部分的人——管理层人士使用TR来看看他们如何与另一个人联系上,他们的下属当中有谁和他们想要接触的人有联系。
不过,这群数据设计师创造出的迷人图像的主要危险,在于相信仅仅一幅图像能够定义现实,令现实局限于图片中,使他们认为只要领会和解读出现实就足够了。
相关条目:关于林荫道媒体实验室最新项目“Interactivos?”的
系列报道,
采访Jose Luis de Vicente。






 JL提到的另一个故事大约是同一时期发生在伦敦的,
JL提到的另一个故事大约是同一时期发生在伦敦的,













{kind=link}
{kind=link}
{kind=link}